阈值检测
信息
阈值检测告警规则用于对指标数据持续监控,当指标值超过设定阈值时自动触发告警并通知相关人�员,实现主动运维。
快速上手
第一步:进入创建页
进入 智能告警 → 告警规则 ,点击 新建告警规则 ,选择阈值检测类型后进入配置页。
第二步:配置检测规则
- 选择 生效范围 (资源域,默认为空,必填。选择当前用户有权限的资源域)
- 在指标选取中选择要监控的指标,例如 CPU 使用率,设置聚合方式(如最新值)并添加分组维度(如主机)
- 设置 检测区间 (如 5 分钟,即每次检测会查询5分钟的指标数据)
- 配置 触发条件 :填写结果数据连续超过阈值的次数,并为各告警级别(致命 / 严重 / 警告)填写对应的阈值
- 按需配置数据断档和数据延时策略
第三步:填写告警内容并保存
- 填写 告警标题 (支持变量,如
主机名称: ${host.customizedName},IP地址: ${host.ipv4Address} ${metric}过高) - 按需填写 通知内容 (支持富文本和变量)
- 选择通知策略
- 设置 生效时间 (全部时间 / 周期时间 / 自定义时间)
- 点击保存完成创建
功能说明
检测规则
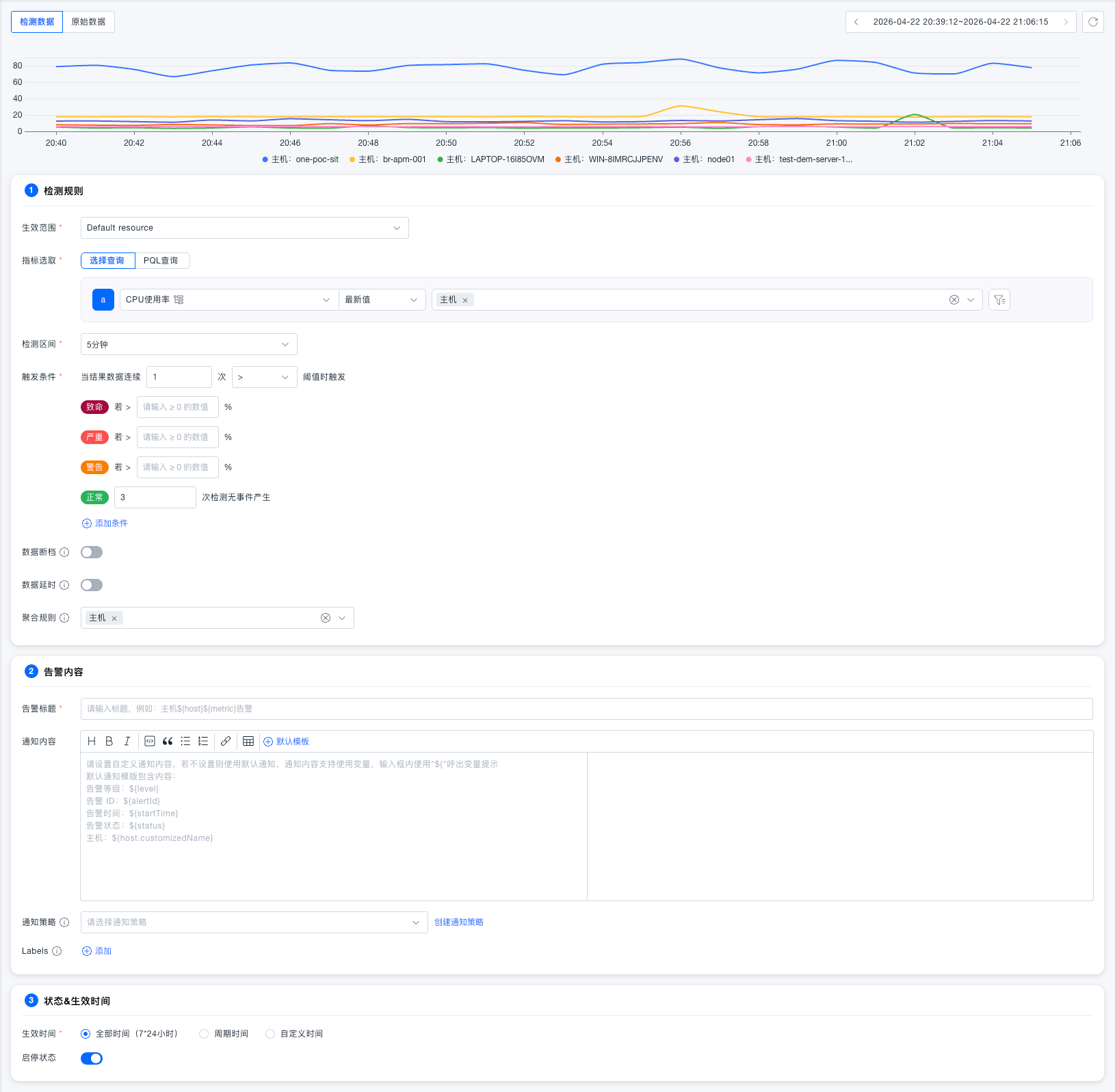
基础配置
| 字段 | 是否必填 | 说明 |
|---|---|---|
| 生效范围 | 是 | 选择告警规则所属的资源域,用于隔离不同资源域的告警配置 |
| 指标选取 | 是 | 支持两种方式:选择查询 、 PQL 查询 |
| 聚合方式 | 是 | 对检测区间内的数据进行聚合,如最新值、平均值等 |
| 分组维度 | 否 | 按指定维度(如主机)分别查询计算 |
| 检测区间 | 是 | 每次查询数据的时间窗口长度,默认 5 分钟 |
提示
检测区间支持1-30min,提供快捷选项并支持手动输入
触发条件
| 字段 | 是否必填 | 说明 |
|---|---|---|
| 连续触发次数 | 是 | 当检测结果连续 N 次超过阈值时才触发告警,避免偶发毛刺引起误报,默认为 1 次 |
| 比较方式 | 是 | 支持 >、>=、<、<=、=等操作符 |
| 致命阈值 | 否 | 指标值超过此阈值触发致命级别告警 |
| 严重阈值 | 否 | 指标值超过此阈值触发严重级别告警 |
| 警告阈值 | 否 | 指标值超过此阈值触发警告级别告警 |
| 一般阈值 | 否 | 指标值超过此阈值触发一般级别告警,默认不展示该等级,可添加 |
| 提醒阈值 | 否 | 指标值超过此阈值触发致命提醒告警,默认不展示该等级,可添加 |
| 正常恢复次数 | 是 | 连续 N 次检测无事件产生时,告警状态恢复正常,默认 3 次 |
高级配置
| 字段 | 是否必填 | 说明 |
|---|---|---|
| 数据断档 | 否 | 开启后,当指定时间内无数据上报时,将指标结果视为 0 参与阈值判断,防止因采集中断导致漏报。默认关闭或开启数据断档触发指定级别的告警 |
| 数据延时 | 否 | 开启后,将查询时间窗口整体前移指定时长,避免因数据链路过长导致漏报。默认开启 ,偏移 1 分钟 |
| 聚合规则 | 否 | 当分组维度下有多个时间序列时,定义聚合粒度。默认按主机聚合,每台主机独立告警;按网络区域聚合,则每个网络区域产生一个包含多主机的告警 |
告警内容
| 字段 | 是否必填 | 说明 |
|---|---|---|
| 告警标题 | 是 | 告警事件的标题,支持变量,如 ${host.customizedName}、${metric},建议包含对象和指标名便于快速识别 |
| 通知内容 | 否 | 告警通知的正文,支持富文本编辑和变量插值。 |
| 通知策略 | 否 | 选择告警触发后的通知渠道和接收人配置,如无可点击创建通知策略新建 |
| Labels | 否 | 为告警规则打标签,便于筛选和分类管理 |
信息
告警标题建议使用变量而非固定文本,便于在告警列表中快速定位问题。
通知内容留空时使用系统默认模板,包含告警 ID、时间、状态和等级等基础信息,满足大多数场景需求。
状态 & 生效时间
| 字段 | 是否必填 | 说明 |
|---|---|---|
| 生效时间 | 是 | 全部时间(7×24 小时) :始终生效; 周期时间 :按工作日/周末等周期设置; 自定义时间 :指定具体时间段生效 |
| 启停状态 | 是 | 控制告警规则是否运行。关闭后规则暂停检测,不产生告警事件,默认开启 |
常见场景
场景:监控生产服务器 CPU 持续高负载 选择 CPU 使用率指标,分组维度设为主机,将致命阈值设为 90%、严重设为 80%,连续触发次数设为 3,避免短暂峰值误报。
场景:非工作时间降低告警敏感度 生效时间选择 自定义时间 ,配置工作日 9:00–18:00 生效,其余时间不发送通知,减少夜间打扰。
场景:主机采集中断时仍能告警 开启数据断档并将断档结果视为 0,配合阈值检测,确保主机 Agent 异常时也能触发告警,而不是静默。
注意事项
注意
修改检测区间或连续触发次数会影响告警的响应延迟:区间越长、次数越多,从异常发生到收到通知的时间越长,请根据业务容忍度合理设置。