日志查询
日志服务支持秒级查询十亿到千亿级别的日志数据。通过日志查询,您可以基于日志查询故障,也可以基于日志解析的字段信息分析业务数据。日志查询支持以下功能:
-
支持将单条日志的信息以列表的形式查看。
-
支持通过聚合统计来发现价值信息,并以可视化图表的方式展示。
-
支持将相似结构的日志分组展示,这将极大的便利您分析过程,您不再需要是基于所有的明细日志分析问题。
前提条件
日志经内置解析流程或自定义的解析流程处理,相关属性或标签已经被解析。
开始使用
首先,通过日志分析>日志查询,即可进入日志查询模式。
平台支持列表、图表、模式识别三种方式查询日志。可以通过切换按钮进入相应的分析场景。
日志列表
支持以列表的形式查看日志。点击每一条日志都可以看到日志的详情页。
搜索框与快捷过滤
 您可以通过搜索框或快捷过滤输入查询条件来搜索日志。点击查询按钮进行日志数据的查询。
您可以通过搜索框或快捷过滤输入查询条件来搜索日志。点击查询按钮进行日志数据的查询。
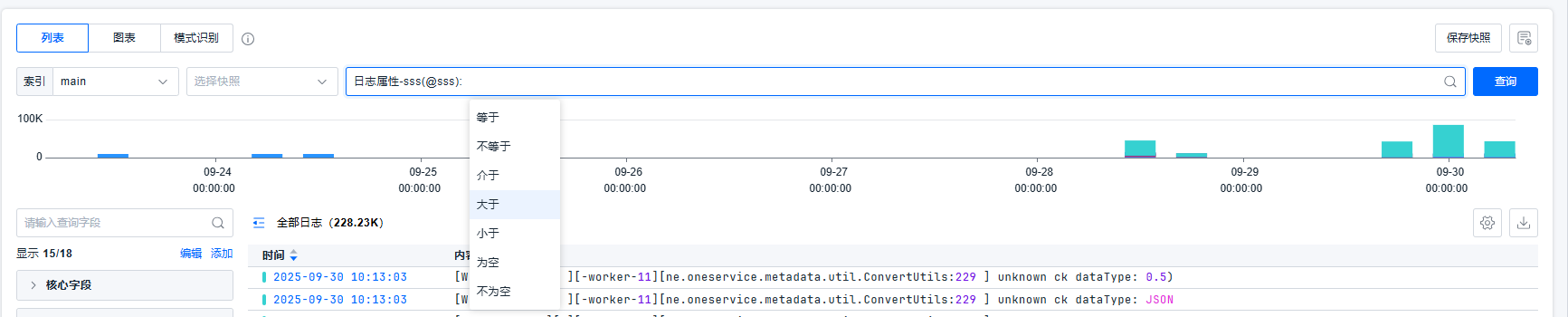
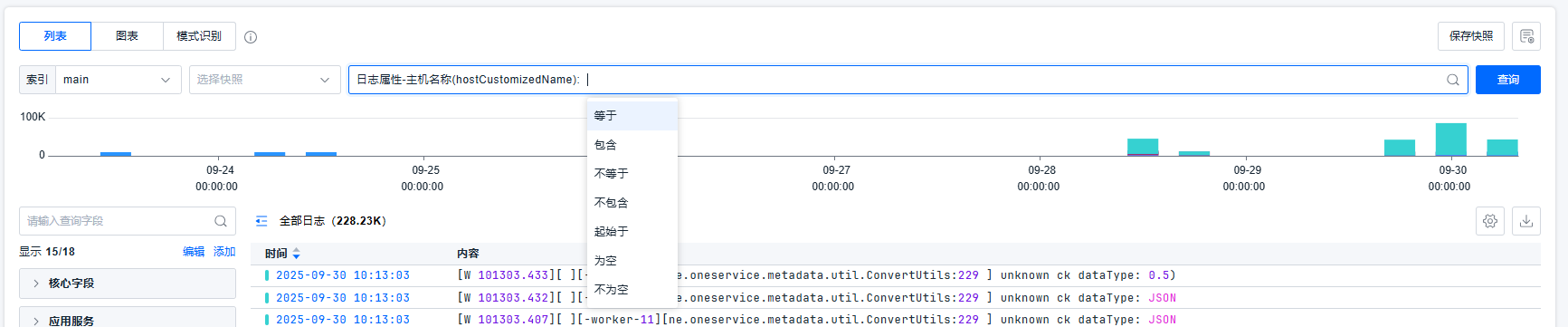
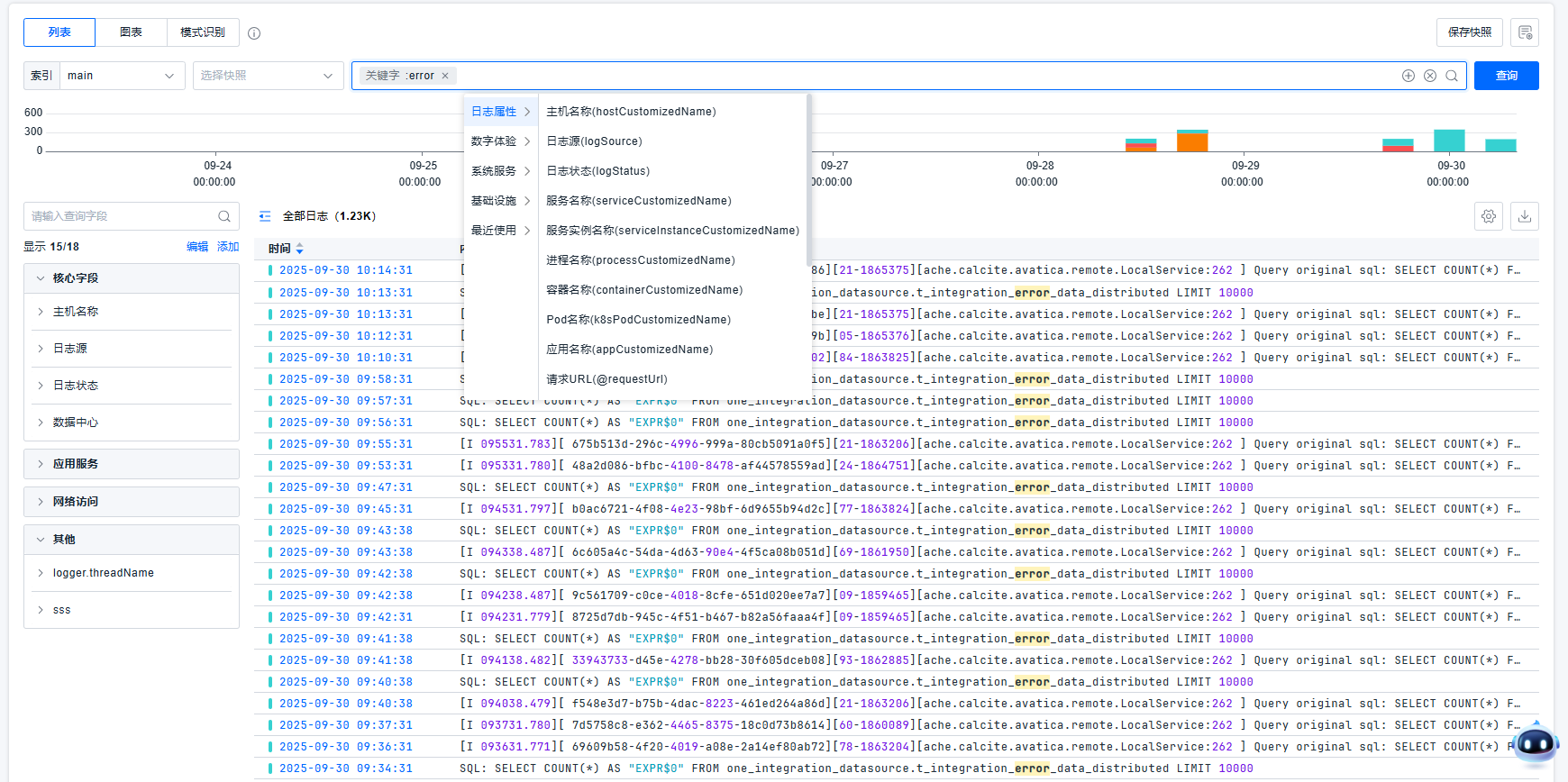
平台提供强大的过滤组件,可以通过关键字、属性、标签信息,以不断缩小、扩大、调整查询范围,以定位问题。平台支持灵活的查询条件:对于数值,平台支持等于、不等于、介于、大于、小于、为空、不为空。对于文本,平台支持等于、包含、不等于、起始于、为空、不为空。
平台内置了一些常用的过滤字段,如:Index 、Host、Source、Status等核心字段,帮助您快捷过滤日志。
快捷过滤提供了当前过滤条件下的日志数据的统计信息,支持仅查看、查看全部、切换选项 按钮便捷选择您需要过滤的字段。
平台支持一键查看对应的图表情况。

针对快捷过滤中的字段,支持显示列/删除列,隐藏字段,关联到标准属性的操作。
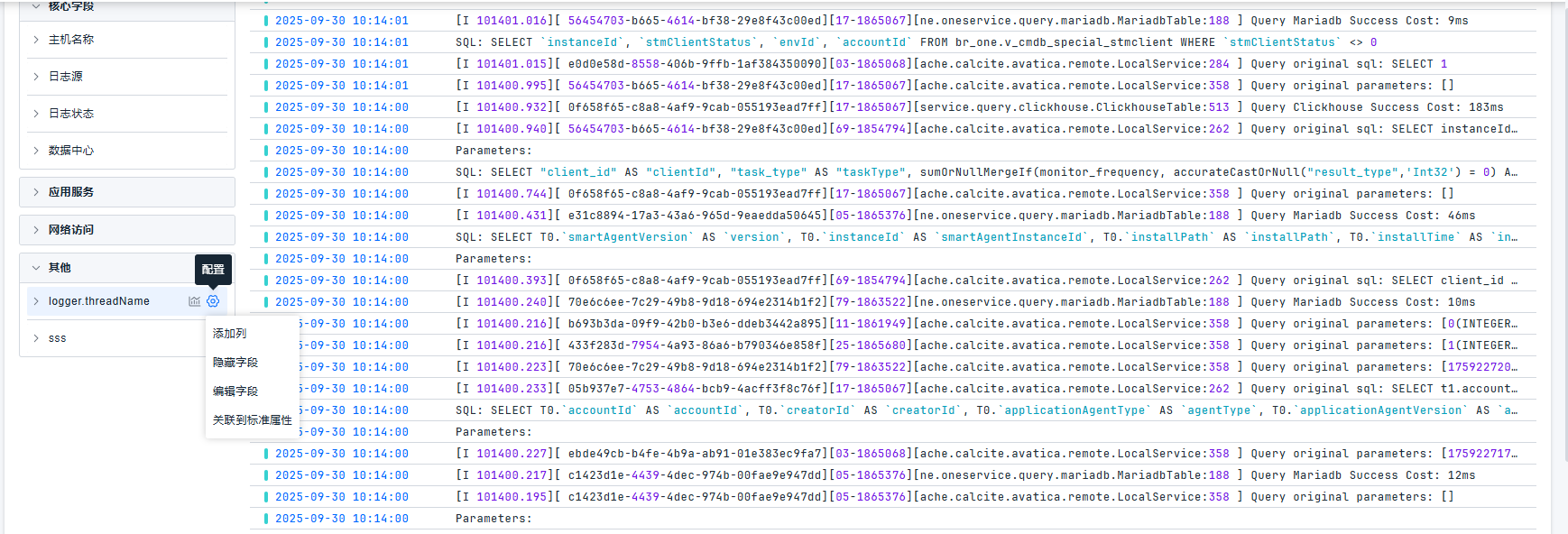
定义字段
当内置的过滤字段不满足使用时,可以通过点击添加按钮或通过日志详情页中的属性直接添加。
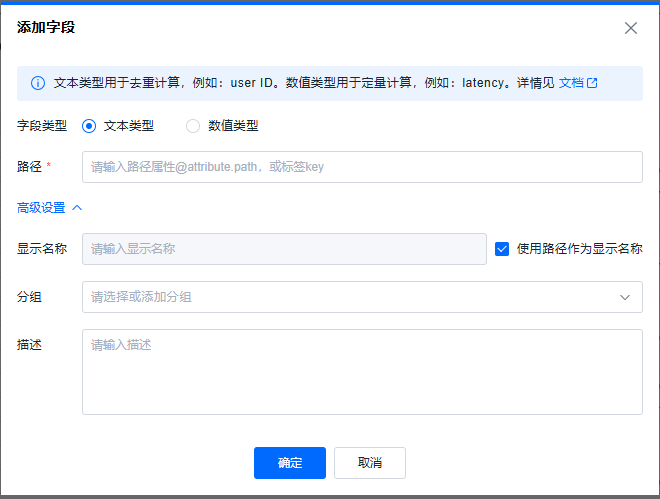
添加的字段支持文本和数值类型两种。
文本类型
文本类型的字段,有两种数据源,一种是属性,另一种是标签。
-
要搜索特定属性,添加@以指定正在搜索某个属性。属性搜索区分大小写。搜索包含特殊字符的属性值需要转义或双引号。
- 例如,对于属性my_attribute值为hello:world,使用搜索:@my_attribute:hello:world或@my_attribute:"hello:world"。要匹配单个特殊字符或空格,请使用?通配符。例如,对于my_attribute值为的属性hello world,搜索使用:@my_attribute:hello?world。
-
以下字符被认为是特殊的:+ - = && || > < ! ( ) [ ] ^ " “ ” ~ * ? : \,并且需要使用该字符/进行转义。\您无法在日志消息中搜索特殊字符。
-
对于标签,使用标签key。
高级设置支持设置显示的名称、分组、描述。
- 平台默认勾选使用路径作为显示的名称(不包含@),如果用户需要修改显示的名称,需要取消勾选使用路径作为显示的名称。这个字段仅用于过滤面板字段的显示,对于日志的解析字段没有影响。
- 分组,非必填,支持下拉点选和直接添加一个新的分组项。不填的时候,直接归类为其它。
- 描述,非必填。
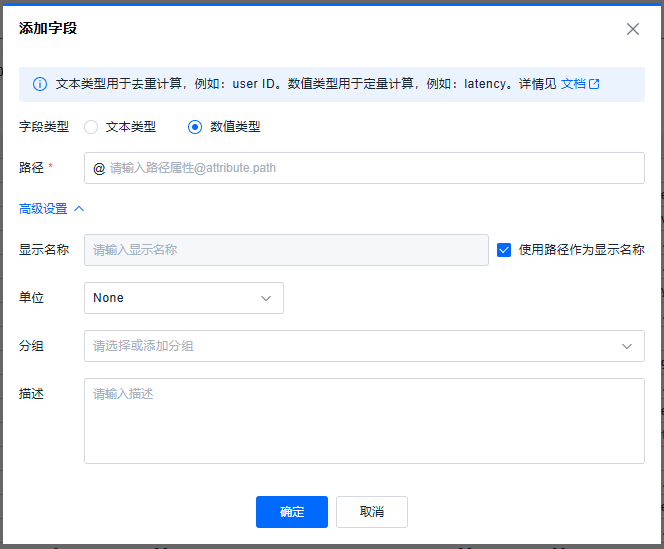
数值类型
- 为了搜索数值属性,首先将其添加为字段。然后,您就可以使用数字运算符(大于、小于、介于)对数字字段执行搜索。
高级设置支持设置显示的名称、单位、分组、描述。
- 平台默认勾选使用路径作为显示的名称(不包含@),如果用户需要修改显示的名称,需要取消勾选使用路径作为显示的名称。这个字段仅用于过滤面板字段的显示,对于日志的解析字段没有影响。
- 支持配置单位,单位起到查询统一的效果,默认为None,下拉项支持:None/B/KB/MB/GB/TB/PB/μs/ms/s/min/h/day/week。不同源的数据可能和过滤属性设置的单位不一致,该一致需要您通过算术处理器配置以保证一致性。
- 分组,非必填,支持下拉点选和直接添加一个新的分组项。不填的时候,直接归类为其它。
- 描述,非必填。
查询效果
由于日志量较大,尽可能的选择准确的时间范围以便提升搜索效率。被搜索匹配的字段会高亮显示。
平台提供状态分布图以状态维度查看日志数量。点击或滑动可以过滤显示相应时间范围内的日志。

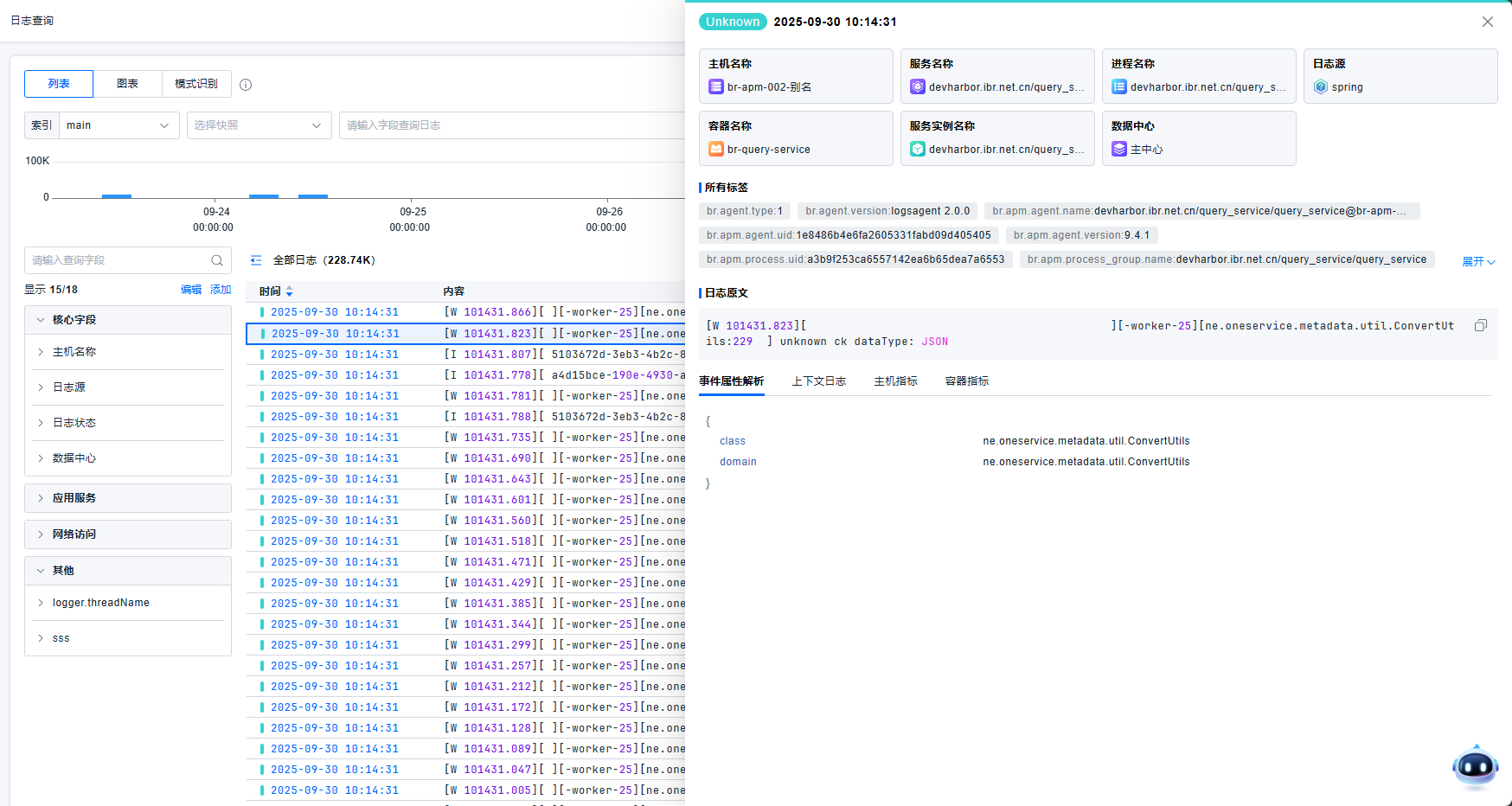
日志详情页
日志详情页显示我们针对该条日志采集到的所有明细信息。
针对重点信息,我们将以卡片的形式展示,入主机、服务、进程、Source等。
针对标签,将包括采集时日志自带的内置标签,我们基于采集逻辑自动附加的标签,以及您在采集配置中配置的标签信息。
我们会存储日志的原文,并在事件解析属性中显示日志自身解析的属性信息,这将包括通过处理流程提取或扩充的结构化信息。
我们支持您基于该条日志查看上下文信息,这将基于当时采集该条日志的路径、主机信息、日志唯一标识定位,让您体会远程登录主机并打开某个日志文件时的感受,而无需这些繁琐的步骤。
我们支持您基于异常日志发生时查看所在的主机、容器、Pod实体上的指标趋势情况,以帮助您进行关联分析。同时,也可以查看实体的属性信息,来辅助进行判断是否需要扩容��等操作。
图表分析
该模式支持通过多个维度统计某个属性的值或日志的条数。支持以趋势图、排行、表格的方式查看日志。
趋势图
平台支持趋势图查看日志信息。您可以通过输入条件查询符合预期的日志信息,然后选择要统计的对象以及对应的统计方式,并且支持选择按照最多5个维度查看数据。针对要统计的信息必须是快捷过滤中被定义过的字段。

统计对象:
对于定性(文本),所有日志对应的统计方式固定为count,对于其它定性的维度,统计方式固定为 Count unique。
对于定量(数值),统计方式默认显示Avg,支持点选切换:Avg、Max、Median、Min、Pc75、Pc90、Pc95、Pc98、Pc99、Sum。
维度:
默认情况下显示为Everything。表示不用按照维度拆分数据。用户点击Everything,会显示所有的定性过滤属性。
如果您需要对展示的统计信息顺序有要求,可以配置排序,例如:统计 service unique count 按照 status top 5 count process
它代表的含义是:按照状态统计服务数量的TOP5,显示的顺序按照进�程的数量,进程数量大的靠前,进程数量小的靠后。
排序支持定性和定量两种。
对于定性(文本),下拉显示:all、其它定性维度。all 对应的统计方式固定为count,对于其它定性的维度,统计方式固定为 Count unique。
对于定量(数值),统计方式默认显示Avg,支持点选切换:Avg、Max、Median、Min、Pc75、Pc90、Pc95、Pc98、Pc99、Sum。
在维度部分选择Status统计图表,悬浮图表时,会高亮同类型的数据,并基于维度信息显示对应的统计值。
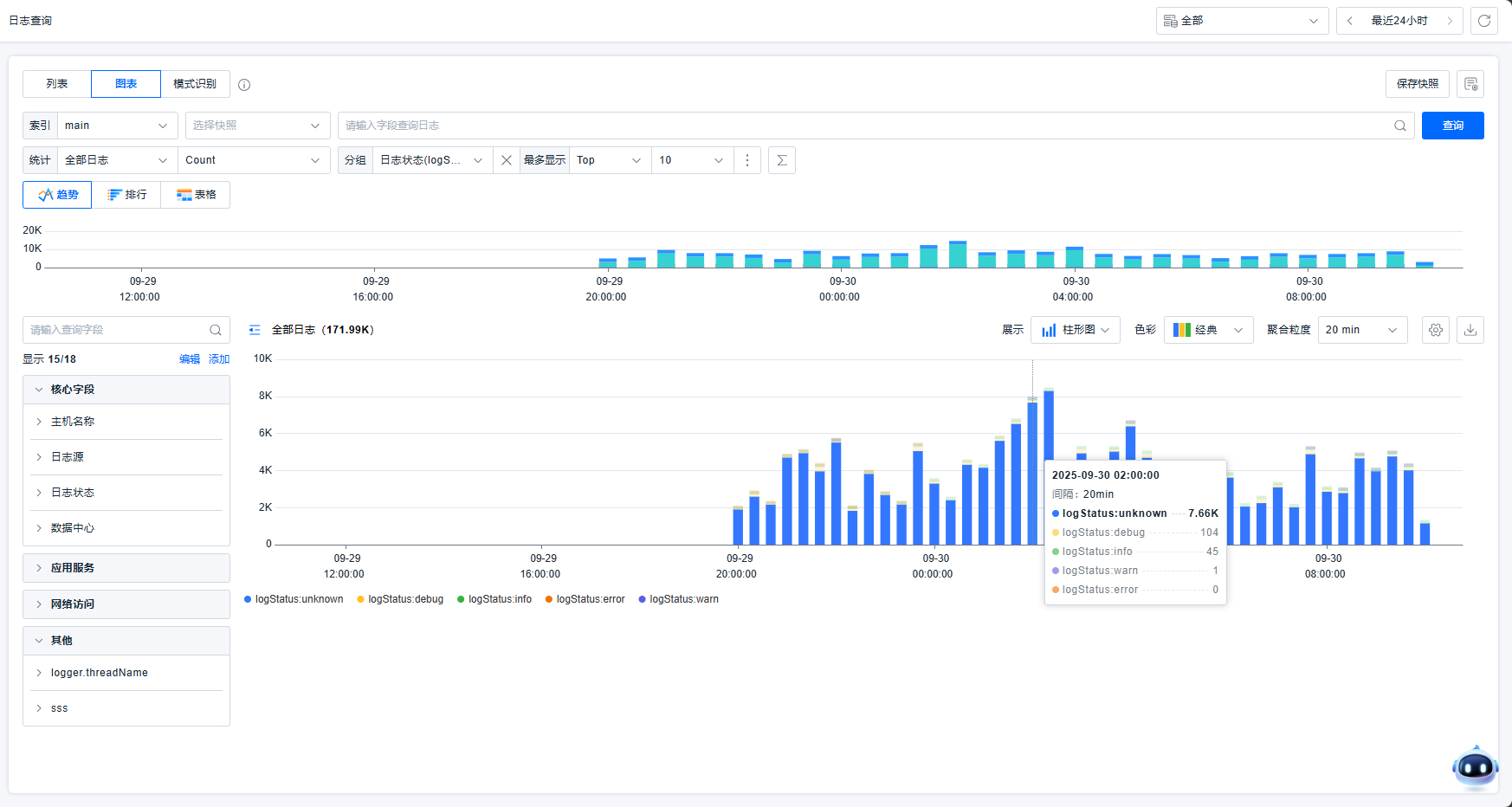
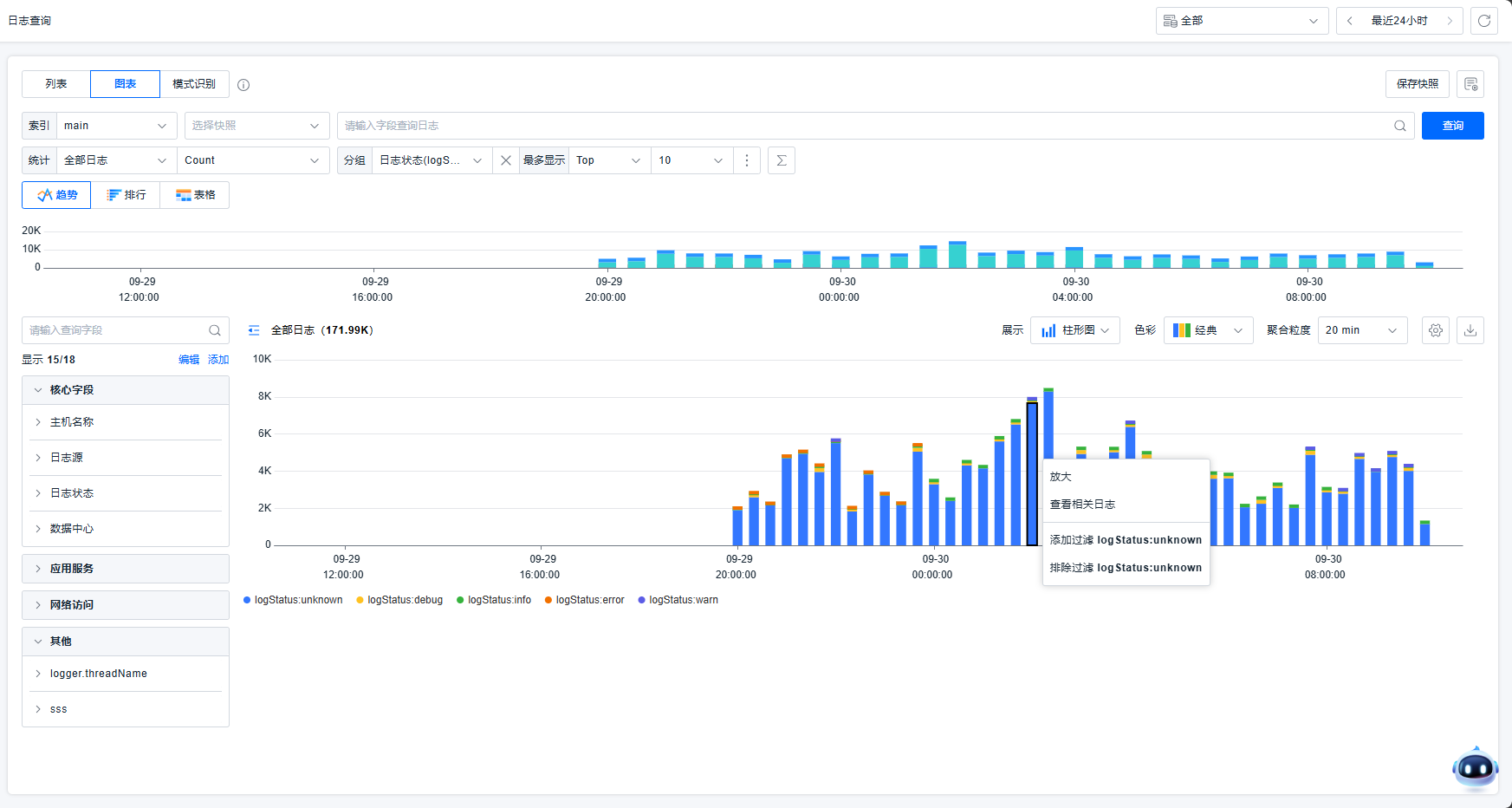
您可以基于图表做便捷的过滤或跳转。例如,点击后,可以实现放大、查看相关日志、添加过滤、排除过滤的操作。放大相当于查看该时间范围的数据。
查看相关日志,将在抽屉中显示该柱状图对应的日志明细列表。相关的过滤条件会显示在抽屉中的过滤框中。您可以针对该部分数据做更细粒度的数据过滤,并查看日志详情。
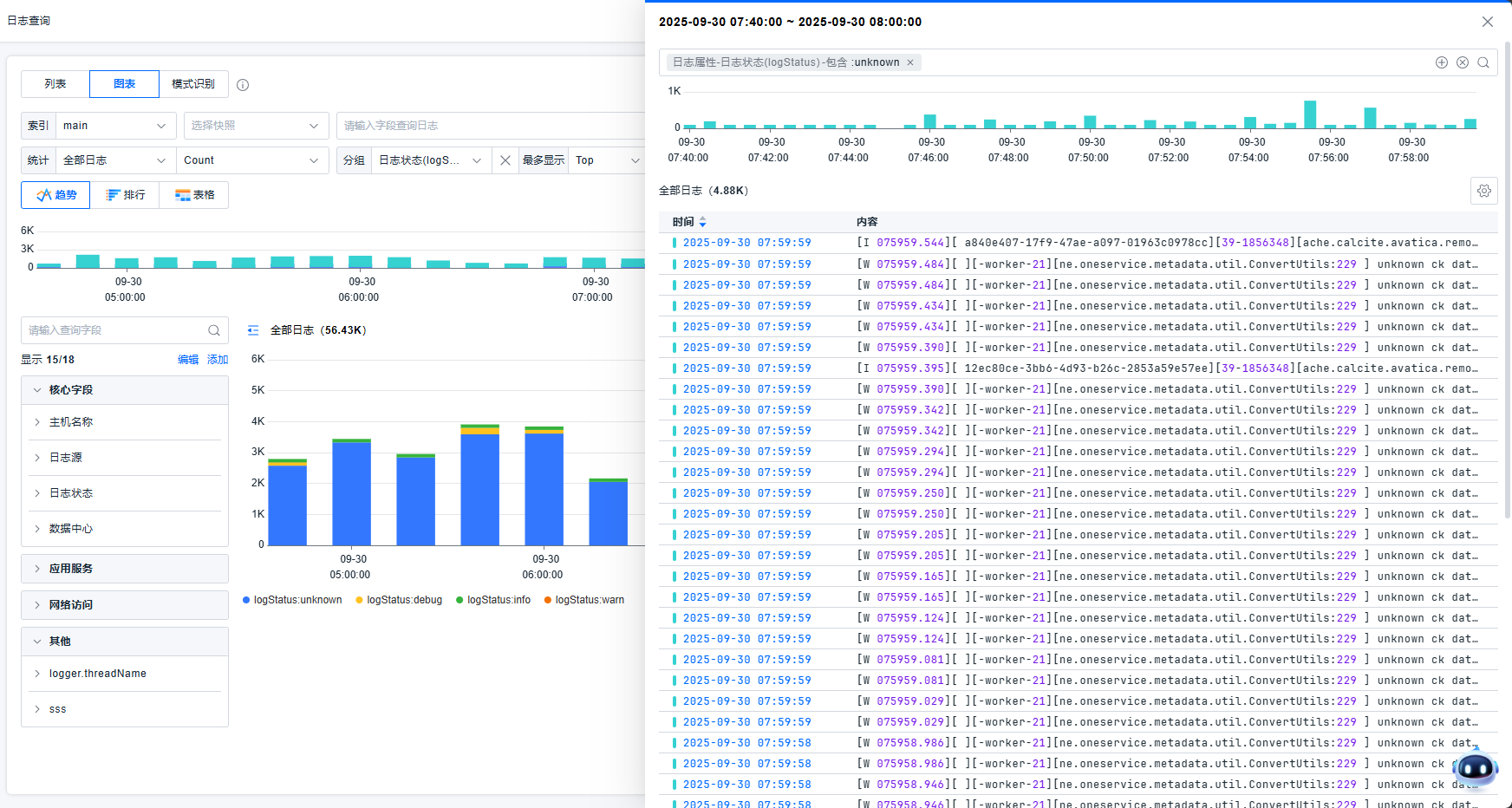
该列表支持配置表头与行数。支持隐藏与显示状态分布图。
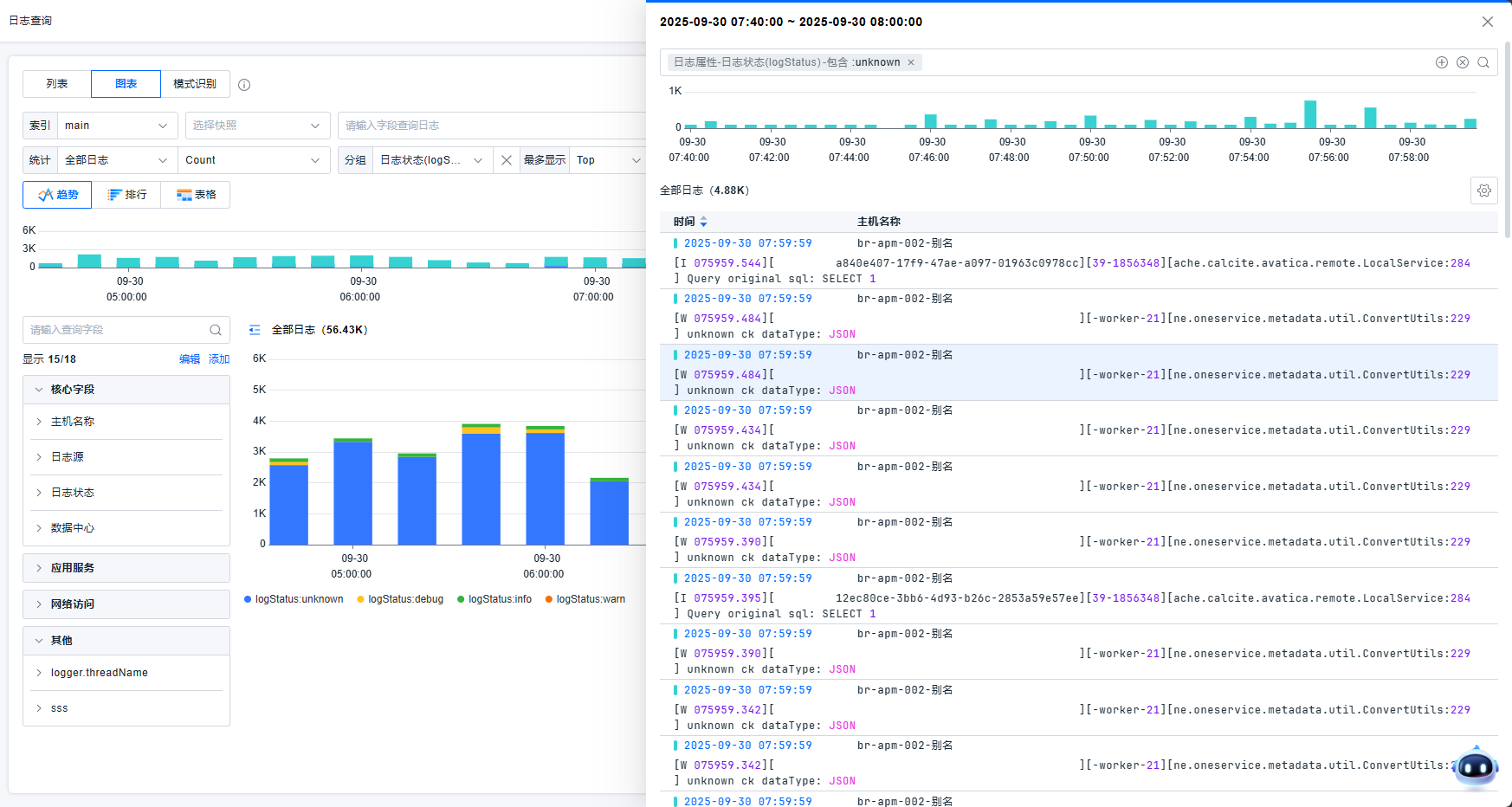
排行
平台支持以排行的方式查看日志信息。您可以选择一个维度信息进行排序。如果您需要多个维度查看建议选择表格的方式。针对每一条统计均支持查看相关日志、添加或排除过滤条件。
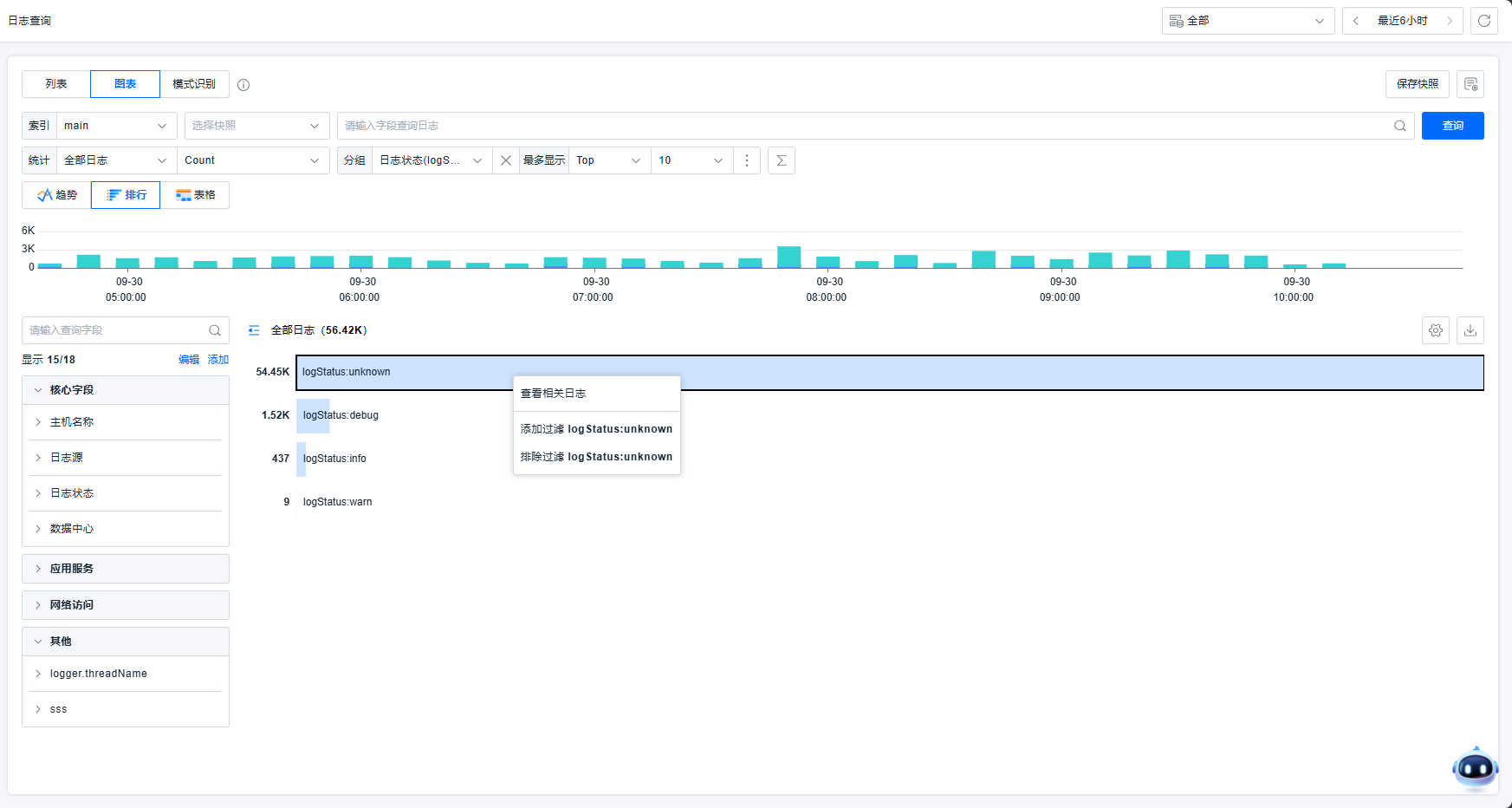
表格
平台支持表格查看日志信息。
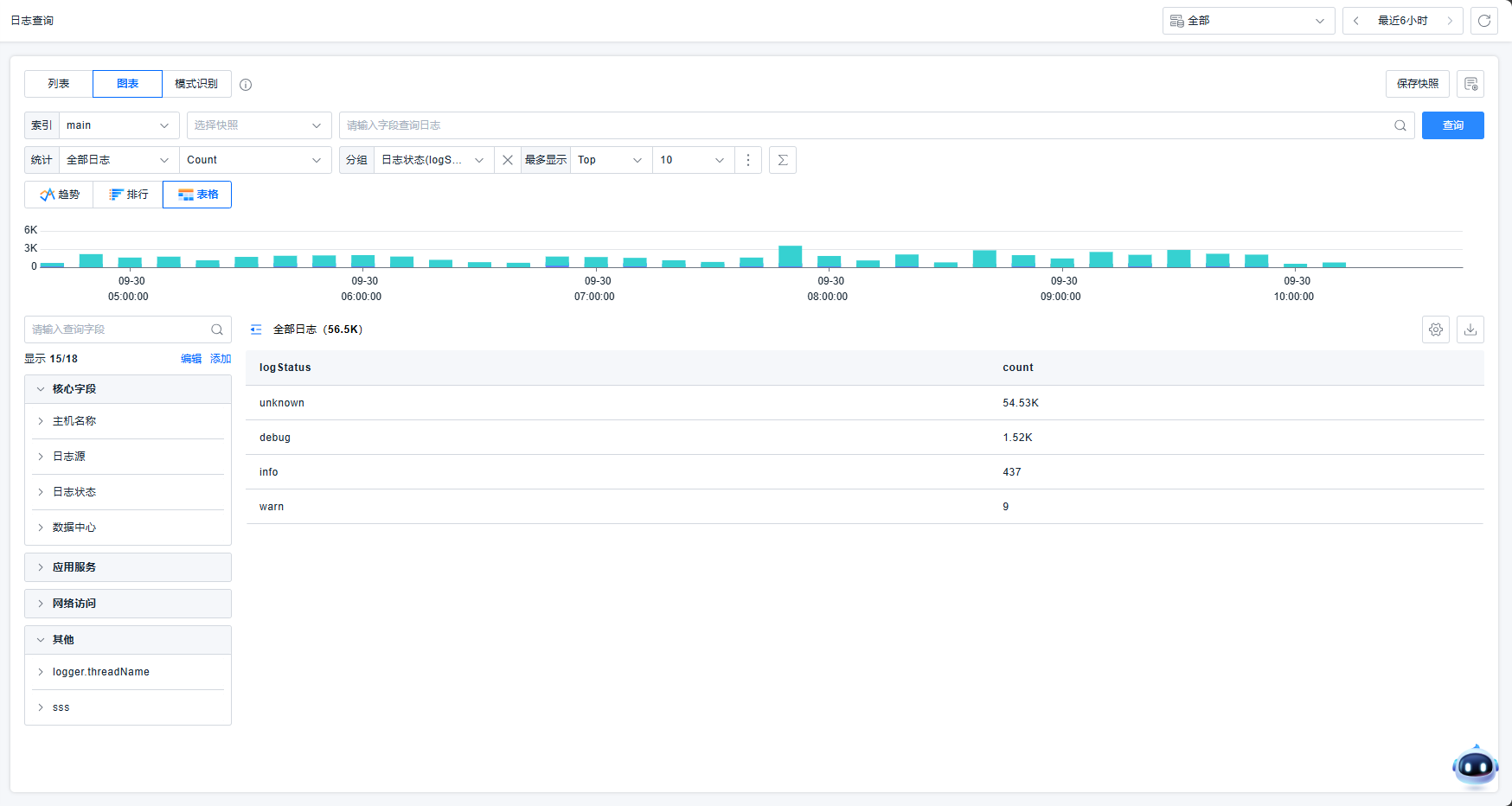
表格按照每个维度分别统计该维度的总数,并且支持按照维度不断细分。在该示例下:
表格第一行表示全部维度下,日志的个数。
表格第二行表示logstatus是unknown时,日志的个数。
表格第三行表示logstatus是debug时,日志的个数。
通过这种方案,可以很直观的了解各维度下的数据的统计信息,对用户分析问题比较友好。
模式识别
提供日志事件的实时分析和聚类能力,从而快速识别异常。平台支持按照自定义维度&数据的文本相似度&日志状态,查看某个属性的值或日志的条数。
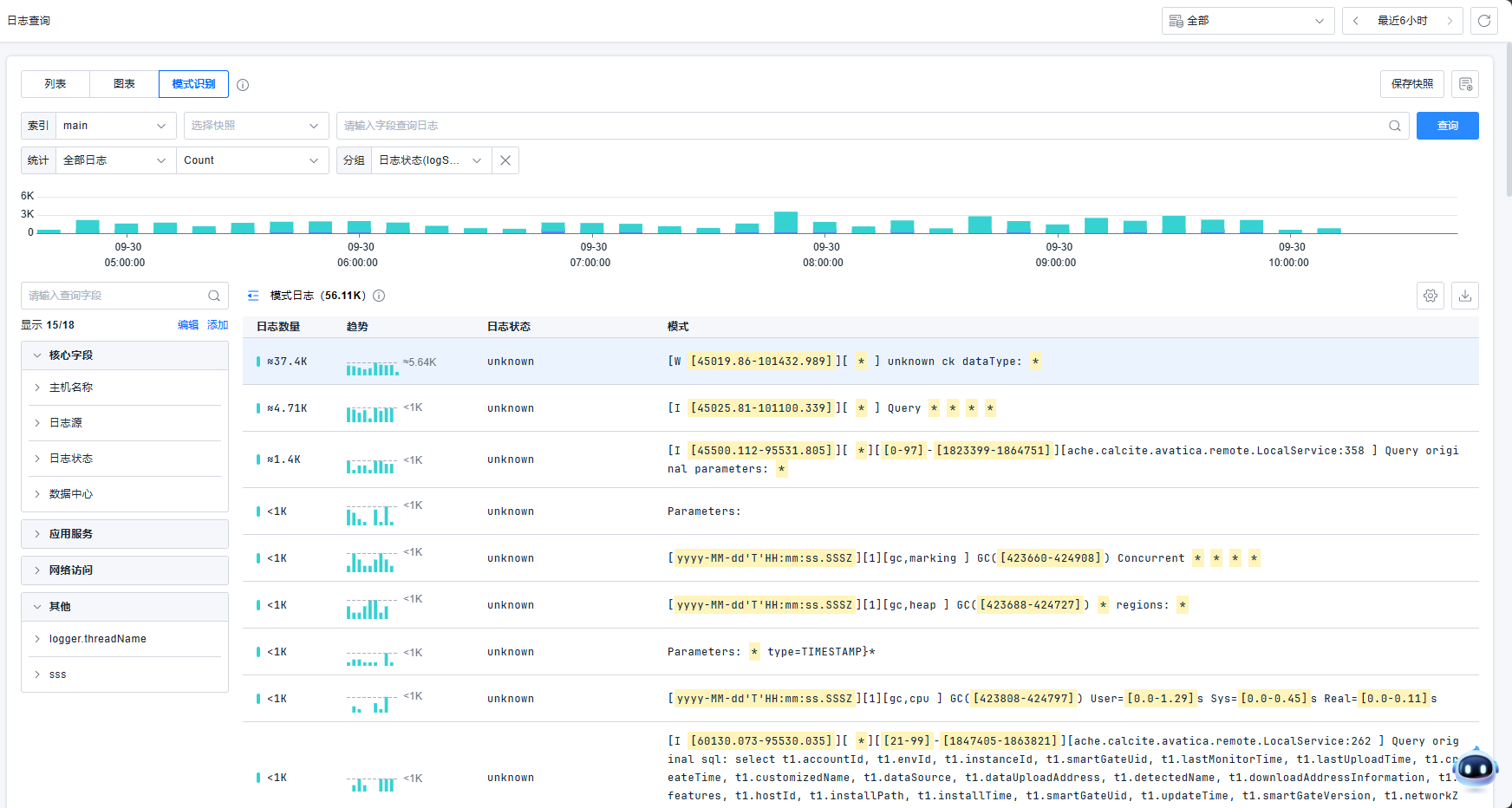
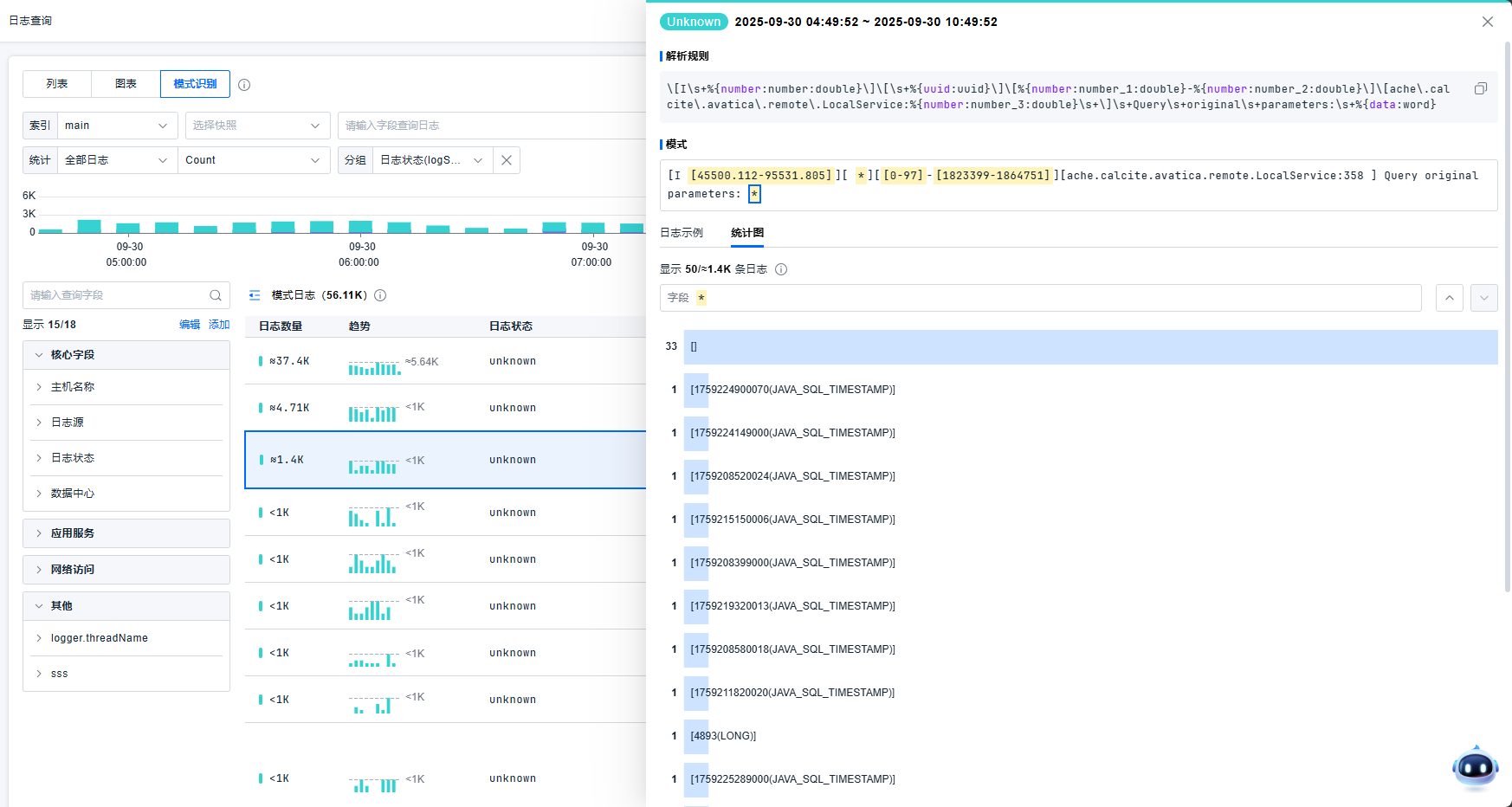
模式详情页显示最严重日志等级、模式识别语句。支持明细和统计图两种查看方式。明细日志列表,用户可以点击查看日志详情。平台基于随机采样的2000条日志数据生成统计图表。日志示例最多展示50条。
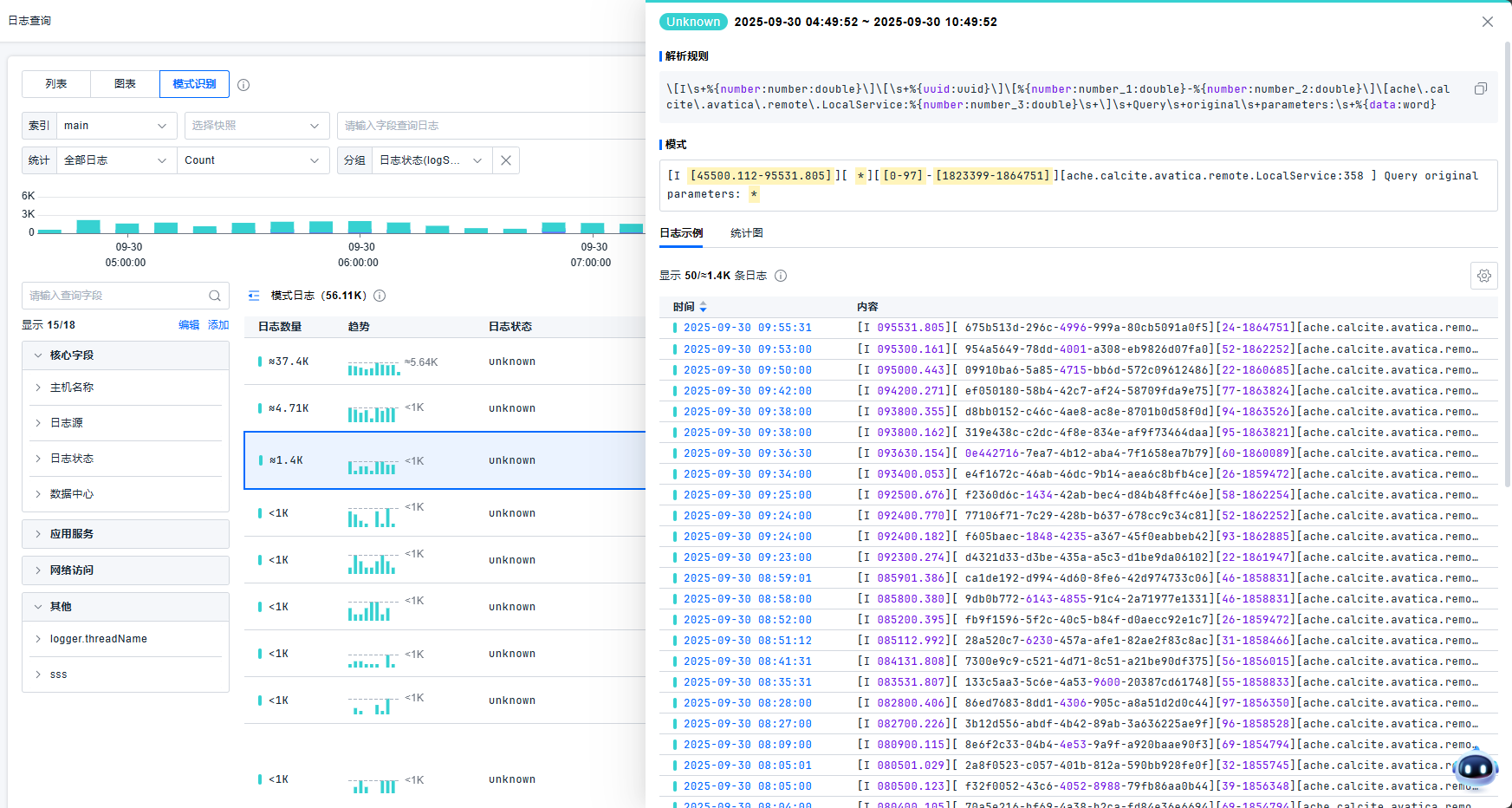
点击统计图,可以查看针对每个字段统计的TOP数据。支持使用全量统计和采样统计两种方式。支持下一项上一项切换字段。点击黄色的区域,可以直接定位到该字段的统计。
值个数小于50个时按照枚举展示,大于50个则采用图表展示。
属性
预置(保留)属性:是随着日志自动提取的属性。平台采集数据时,预处理阶段需要获取的字段,该类型的数据并不是完全基于解析的日志信息获取,也可以通过获取日志的关联元数据获取。该部分的数据需要存储,支持过滤。
标准属性:是组织命名约定的支柱。通过标准属性模块定义的属性,该标准属性起到统一概念的作用,是一个企业内部的日志使用标准,希望实现概念统一,格式目录一致的效果。另外,不同的解析属性可以通过配置关联,关联到同一个标准属性。这样,用户可以将不同路径的属性关联到同一个标准属性,可以基于标准属性来过滤。
例如,客户端 IP 可能具有各种日志�属性,例如clientIP、client_ip_address、remote_address、client.ip等。请求的执行时间可以用exec_time、request_latency、request.time_elapsed等表示。标准属性一方面希望指导企业在实际输出日志的时候用统一的属性名,另一方面也实现了,客户可以灵活的将解析属性关联到标准属性上。
将解析属性关联到标准属性后,用户可以使用解析属性和标准属性排障,建议用户使用标准属性,可以简化来自不同源或异构的内容的关联。促使用户使用标准属性来代替别解析属性。
解析属性:用于查询。基于解析规则识别的属性,该属性并没有上升到标准属性的程度,需要通过配置来定义成标准属性。当解析属性关联到标准属性,原来的解析属性仍然是有效的,但是一般用户将不再使用该字段,而是使用标准属性,这样才能使来自不同来源的内容关联更加直接。如果用户配置的解析属性名称与标准属性的名称相同,平台将认为该解析属性就是标准属性。
过滤属性:基于索引日志用户定义的标签和属性和部分平台内置的过滤属性,用于定性或定量数据分析。基于标准属性或者解析属性重新定义的过滤属性,被定义后的属性在后续收集到的日志生效,历史的日志不会生效。需要注意mapper类型的字段、geoip 、url 解析的属性均属于内置的过滤属性。
预置属性
预置属性是默认要求采集的字段。
| 字段名 | 描述 |
|---|---|
| indexName | 用户层抽象出来的索引名字 |
| pattern | Grok语句 |
| uid | 日志唯一ID标识 |
| traceId | Trace id ,用于链路追踪 |
| spanId | spanId,用于链路追踪 |
| sessionId | session id,rum会话ID |
| actionId | action id , rum 动作ID |
| deviceId | 设备ID,后端host&终端设备的统称 |
| deviceName | 设备名字 |
| serviceId | 服务id,APM中的概念 |
| serviceName | 服务名 |
| processId | 进程唯一标识 |
| processName | 进程名字 |
| appId | app id,rum概念 |
| appName | app 名称,rum概念 |
| status | 日志状态,有七种EmegencyErrorWarnNoticeInfoDebugUnknown |
| source | 日志来源,例如java、nginx |
| body | 日志原文 |
| monitorTime | 日志采集时间 |
标准属性(初始)
| 属性路径 | 显示名称 | 所属分组 | 格式 | ETL解析 |
|---|---|---|---|---|
| network.client.geoip.country.name | Country Name | Geoip | string | .country |
| network.client.geoip.district.name | District Name | Geoip | string | .district |
| network.client.geoip.city.name | City Name | Geoip | string | .city |
| http.url_details.host | URL Host | Web Access | string | .host |
| http.url_details.port | URL Port | Web Access | string | .port |
| http.url_details.path | URL Path | Web Access | string | .path |
| http.useragent_details.browser.family | Browser | Web Access | string | .browserName |
| http.useragent_details.os.family | Os | Web Access | string | .osName |
过滤属性(初始)
基于内置属性生成的过滤属性:预置属性不支持编辑。
| 属性路径 | 显示名称 | 所属分组 | 格式 |
|---|---|---|---|
| -- | Index | 核心字段 | string |
| -- | Source | 核心字段 | string |
| -- | Host | 核心字段 | string |
| -- | Service | 核心字段 | string |
| -- | Status | 核心字段 | string |
基于解析器生成的过滤属性:geoip/useragent/ url
| 属性路径 | 显示名称 | 所属分组 | 格式 | ETL解析 |
|---|---|---|---|---|
| network.client.geoip.country.name | Country Name | Geoip | string | .country |
| network.client.geoip.district.name | District Name | Geoip | string | .district |
| network.client.geoip.city.name | City Name | Geoip | string | .city |
| http.url_details.host | URL Host | Web Access | string | .host |
| http.url_details.port | URL Port | Web Access | string | .port |
| http.url_details.path | URL Path | Web Access | string | .path |
| http.useragent_details.browser.family | Browser | Web Access | string | .browserName |
| http.useragent_details.os.family | Os | Web Access | string | .osName |
标签
标签是平台或用户定义的日志标识。
平台支持自动提取标签,支持探针内置标签,支持手动基于路径配置标签。
平台内置的标签如下:
| 字段 | 描述 |
|---|---|
| log.source | 日志文件路径,或者日志内容来源(windows event之类) [必填] |
| br.agent.version | 日志探针版本[必填] |
| br.machine.guid/deviceId | machineGUID [必填] br.machine.guid,deviceId两都上报 |
| br.apm.process.uid | APM 进程 uid (进程实例) [非必填] |
| br.apm.process_group.name | APM 进程组名 [非必填] |
| br.apm.agent.uid | APM 应用探针 uid [非必填] |
| br.apm.agent.version | APM 应用探针版本 [非必填] |
| br.process.technology | 进程技术类型 拼接方式: key:version [非必填] |
| container.image.name | 容器镜像名 [非必填] |
| container.name | 容器名 [非必填] |
| container.id | 容器id [非必填] |
| br.kubernetes.cluster.name | 平台打的 k8s 集群名 [非必填] |
| kubernetes.node.system_uuid | [非必填] |
| kubernetes.cluster.id | [非必填] |
| kubernetes.namespace.name | [非必填] |
| kubernetes.pod.uid | [非必填] |
| kubernetes.pod.name | [非必填] |
| kubernetes.container.name | [非必填] |
| kubernetes.deployment.name | [非必填] |
| host.name | 主机名 [必填] host.name,deviceName两都上报 |
| br.agent.type | 日志探针类型 [必填] 枚举:主机: 1: server探针Linux 2 : server端探针linux-Arm 3:server 端探针windows设备: 100 : android 101 : ios 102 : web |
| br.token | 数据上报 token (账号guid) [必填] |
| host.ip | 主机 ip [非必填] |
| br.agent.type | 日志探针类型 [必填] 枚举:主机: 1: server探针Linux 2 : server端探针linux-Arm 3:server 端探针windows设备: 100 : android 101 : ios 102 : web |
| tag | 平台打的 tag [有则填] |
关键字
对日志原文进行分词,每个词就是可以被搜索的关键字。
当进行全文检索时,文本数据需要进行分词处理。分词是将原始文本切分成有意义的词汇单元的过程。
首先,原始文本经过字符过滤,去除特殊字符、标点符号等,只保留有意义的内容。
然后,文本被送入分词器,分词器将文本切分成词汇单元。分词器根据不同的规则和算法进行切分,如以空格为界限或者根据语言特性进行切分。
接下来,词汇单元经过一系列的词汇过滤器进行处理。词汇过滤器可以去除停用词(如“a”、“an”、“the”等常用词汇),将词汇转换为小写形式,或进行词干提取等操作,以减少冗余和提高搜索的准确性。
在分析过程中,每个词汇单元都被赋予一个位置标记,表示在原始文本中的位置信息。这个位置信息在后续的搜索和排序中很重要。
最后,分词后的词汇单元和位置信息被组织成倒排索引的形式。倒排索引将每个词汇映射到包含该词汇的文档列表,以支持快速的全文搜索。
分词过程在全文检索中起着关键作用,它使得搜索引擎能够理解和处理文本数据,提高搜索的准确性和效率。分词过程可以根据需要进行配置,并支持自定义的分词规则和过滤操作。